
Just over a year ago I reported here on the blog my social detox/rehab.
In short, I stopped using social media (I’ll still write about the benefits of being out of networks).
Twitter has always been the network where I’ve been most active, so much that in 10 years I’ve created over 10,000 tweets.
One of the main reasons I quit social media is much more linked to consumption, in other words, rolling out the timelines.
But content creation is something I want to keep. That’s what this blog is for.
What to do with 10,000 tweets? Sure, a lot is totally crap, but the content is mine and I want to have control.
So I came up with the challenge: Migrate all content created on Twitter by me in the last 10 years to my blog.
TL;DR
👉 I sucessufully migrated all my tweets to my blog: https://twitter.jaydson.com
👉 It was a fun process
👉 I created an open source project so other people can do it too: tweets-to-md
Is it possible to have access to your data on Twitter?
Yep 👍
For those interested, here’s the link: https://help.twitter.com/en/managing-your-account/how-to-download-your-twitter-archive.
Twitter gives us the option to download our data, not only tweets, but also direct messages, personal data and more.
See the image below for the folder and file structure that Twitter makes available.
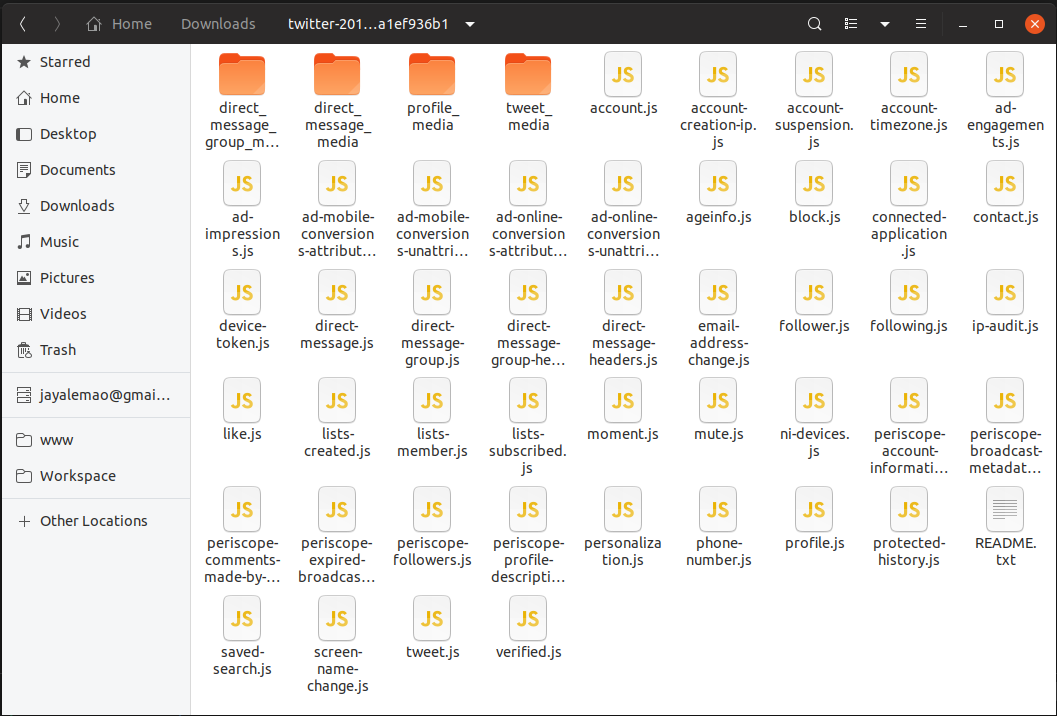
Note that all files have the .js extension. That’s exactly what it sounds, Twiiter delivers our data in JavaScript.
This brings us some advantages, but at the same time limits the possibilities.
For developers, understanding the file structure and executing JavaScript code may not be a big challenge, but what about the rest of the people?
I’ll tackle this problem later (maybe a web solution where anyone can upload tweets and generates a website 🤔).
Data structure
Let’s take a look at the structure.
This is the code from the account.js file (I removed sensitive information):
window.YTD.account.part0 = [ {
"account" : {
"phoneNumber" : "+55****",
"email" : "[email protected]",
"createdVia" : "web",
"username" : "jaydson",
"accountId" : "17294602",
"createdAt" : "2008-11-10T20:48:02.000Z",
"accountDisplayName" : "Jaydson Gomes"
}
} ]
The logic of these files is based on a global namespace: YTD (your twitter data 🤔).
Each file adds its own context and data within this namespace, so if we execute all JS files in the browser, we’ll have the YTD global variable containing all of our data.
In practice this is not feasible, mainly because of the tweet.js file.
Note the createdAt property above, I’m on Twitter since 2008, it’s been over 10 years of tweets.
My tweet.js file is 13,6MB !.
That gives about 13600000 bytes: 13 million six hundred thousand characters 😮!
See below the structure of a tweet. For obvious reasons, I’m just showing the first record, in this case my last tweet.
window.YTD.tweet.part0 = [ {
"retweeted" : false,
"source" : "TweetDeck",
"entities" : {
"hashtags" : [ ],
"symbols" : [ ],
"user_mentions" : [ ],
"urls" : [ {
"url" : "https://t.co/OcqN37iCFo",
"expanded_url" : "https://jaydson.com/social-detox-rehab/",
"display_url" : "jaydson.com/social-detox-r…",
"indices" : [ "19", "42" ]
} ]
},
"display_text_range" : [ "0", "42" ],
"favorite_count" : "5",
"id_str" : "1034898743869534208",
"truncated" : false,
"retweet_count" : "2",
"id" : "1034898743869534208",
"possibly_sensitive" : false,
"created_at" : "Wed Aug 29 20:21:02 +0000 2018",
"favorited" : false,
"full_text" : "Social Detox/Rehab\nhttps://t.co/OcqN37iCFo",
"lang" : "da"
}]
Converting tweets to posts
I’m using Hugo as platform for my blog.
Since Hugo is an SSG (static site generator), where the structure is based on the filesystem, to create a new post a markdown file is enough.
For metadata Hugo (and the vast majority of SSGs) uses the Front Matter standard.
I am using the YAML pattern in Front Matter, which uses --- as marker. Here’s an example metadata for a blog post:
---
author: Jaydson Gomes
categories:
- blog
- web
date: "2019-09-26T10:38:17Z"
draft: false
image: /images/2019/09/jaydson.com-2019.png
slug: mudancas-no-blog-2019
tags:
- blog
- web
title: Mudanças no Blog 2019
---
To convert tweets to posts all I had to do was create markdown files with the tweet content and the required metadata.
I ended up creating a project on GitHub just to handle this conversion: tweets-to-md.
For those who want to use it:
👉 Clone: git clone [email protected]:jaydson/tweets-to-md.git
👉 Copy the tweet.js file to the root
👉 Change the config.js file with the necessary information
See an example:
const config = {
frontMatterTemplate : `
---
author = "Jaydson Gomes"
categories = ["tweet"]
date = "{TWEET_DATE}"
draft = false
image = "{TWEET_IMAGE}"
slug = "{SLUG}"
tags = ["tweet"]
title = """{TITLE}"""
tweet = true
tweet_url = "https://twitter.com/jaydson/status/{TWEET_ID}"
---
{CONTENT}
`,
tweetMediaPath: '/images/tweet-media'
}
export default config;
👉 Create the ./posts dir
👉 Install the dependencies npm install
👉 Change the first line of tweet.js:
export const tweets = [ {
This is to ignore the global namespace logic mentioned at the beginning, so we can simply import a JavaScript module containing all tweets.
Look at tweets-to-md the first line:
import { tweets } from './tweet';
👉 Run the script with npm start
tweets-to-md scans all tweets and creates markdown files applying metadata and content.
Here’s an example of what my last tweet looks like after being converted to a blog post:
---
author = "Jaydson Gomes"
categories = ["tweet"]
date = "Wed Aug 29 20:21:02 +0000 2018"
draft = false
slug = "7dffcf9a1433013e157d31838bef66565002208f"
tags = ["tweet"]
title = """Social Detox/Rehab https:..."""
---
Social Detox/Rehab
https://t.co/OcqN37iCFo
At the end of the process, the ./posts folder had 9,452 generated files, ie 9,452 tweets converted to blog posts.
One thing I implemented in tweets-to-md was a filter to ignore replies, which in the end reduced by about 4,000 tweets.
Final result
I noticed that Hugo got a little slow in the build process with so many files.
The easiest solution I found was to generate content with more posts per page.
Another important thing I decided to make in the middle of the process was to separate the original blog posts from the migrated tweets.
For that I created another project on GitHub: twitter.jaydson.com.
This project also uses Hugo, I even used the same theme of my blog for the layout.
I created a theme-specific project too: hugo-paper-tailwind.
To see my tweets in blog posts, please visit: https://twitter.jaydson.com/.
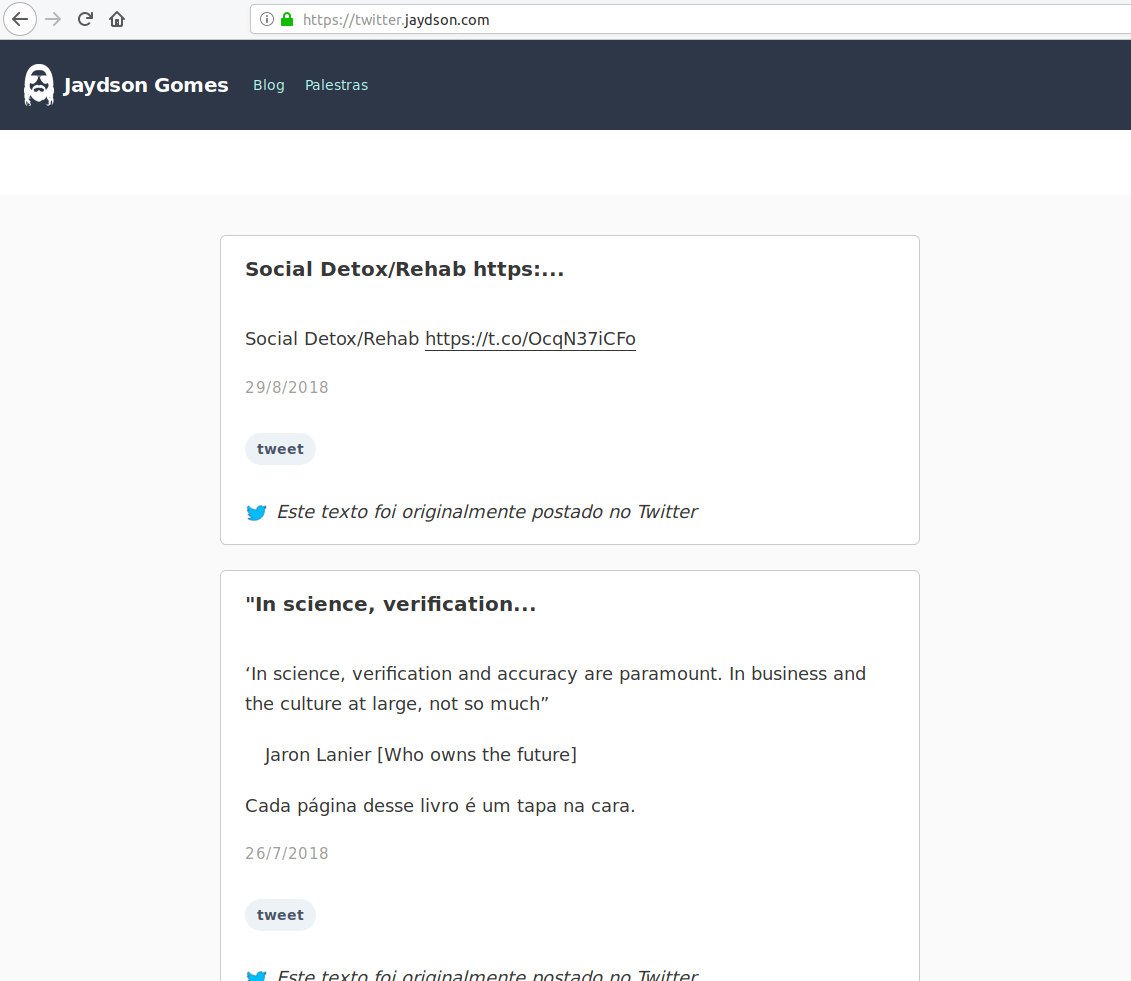
Conclusion
It was a quite fun task.
Now I have my tweets in the form of content on my blog.
I don’t know what will happen to Twitter in the future and I don’t want to go back there, so I reached my main goal.
Unfortunately this solution does not directly impact all people. To perform this process requires some technical knowledge.
When developing the solution I thought of several other possibilities, sime already implemented.
For example, as I no longer use Twitter, but feel the need to create micro-content, I implemented this functionality on the blog.
When creating a post now I can decide if it’s going to be something deeper or shorter, and the cool thing: The content is mine and I decide what I do with it 😉
So, what do you think of the idea?
How about trying to apply this solution to your blog?